지난 "추천시스템과 GNN(Graph Neural Network)"에서는 주로 general recommendation을 다뤘다면 이번에는 sequential recommendation 계열의 알고리즘을 제안한 논문인 "Session-based Recommendation with Graph Neural Networks"(https://arxiv.org/pdf/1811.00855.pdf)를 다루고자 한다.
해당 논문에서 소개한 알고리즘인 SR-GNN은 유저 프로파일을 사용하지 않고 오직 유저의 session sequence만으로 유저가 다음에 클릭할 아이템을 예측하고자 한다. Session sequence는 유저가 현 세션 동안 클릭한 아이템들을 시간 순서대로 나열한 것을 일컫는다.
Notations
전체 아이템의 집합 : $V = {v_1, v_2, ..., v_m}$
익명의 유저의 session sequence : $s = [v_{s,1}, v_{s,2}, ..., v_{s,n}]$
SR-GNN은 $s$를 바탕으로 유저가 $v$의 각 원소를 클릭할 확률을 출력한다. 그 중 예측된 확률이 가장 높은 K개의 item을 선택하여 추천하는 방식이다.
그래프 구성
하나의 session sequence $s$는 하나의 directed graph로 변환된다. $s$ 내의 각 아이템 $v_{s,i}$이 node가 되고 각 $i$에 대하여 $v_{s,i-1}$에서 $v_{s,i}$로 나가는 방향으로 edge가 생성된다. 즉, 각 아이템에 대하여 유저가 그 다음에 클릭한 아이템으로 나가는 방향으로 edge를 연결해주는 것이다. 각 edge의 weight는 source node에서 나가는 edge의 개수로 나뉘어 normalize된다. 각 node는 dimension $d$의 hidden state로 임베딩된다. 이 hidden state들은 여러 번의 propagation을 거쳐 최종 node embedding vector들로 업데이트된다.
Propagation
Propagation은 gated graph neural network(https://arxiv.org/abs/1511.05493) 방식으로 이루어진다.
Session Sequence Embedding Vector 도출
Propagation 완료 후 $s$의 embedding vector $s_h$를 계산해야한다. 앞으로 session에서 $i$번째 아이템 node의 최종 embedding vector를 $v_i$라고 하겠다. 이 단계에서는 $s$의 local embedding vector $s_l$과 global embedding vector $s_g$를 구한 후 둘을 통합한 hybrid embedding vector $s_h$를 구하게 된다. $s_l$은 유저가 마지막으로 클릭한 아이템의 최종 embedding vector $v_n$으로 정의한다. $s_g$는 모든 node의 최종 embedding vector들을 통합한 것으로 다음과 같은 soft-attention 기법을 통해 구한다.

마지막으로 $s_h$를 구하는 식은 다음과 같다. ';'는 concatenation을 의미한다.

Recommendation 결과 출력
각 아이템의 score를 $s_h$와 해당 node의 최종 embedding vector의 내적으로 정의한다.

모든 item의 score를 이어 하나의 vector로 만든 후 softmax 함수를 적용시켜 각 아이템을 클릭할 확률의 예측값을 구한다.

Model Overview
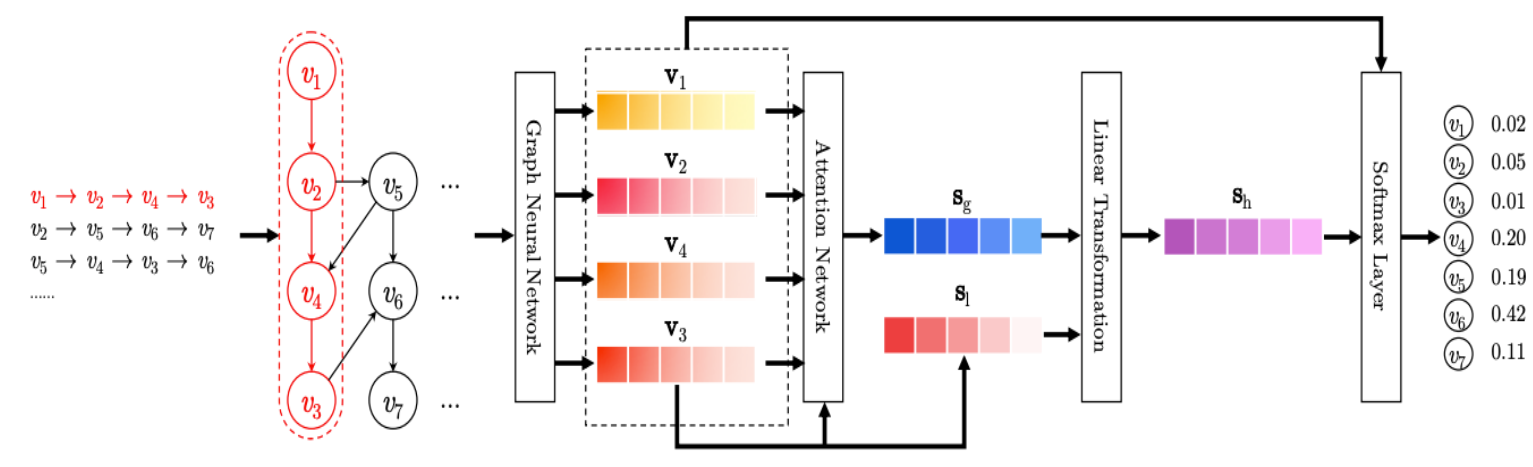
학습
Loss function은 cross-entropy로 정의되었다. Ground-truth label은 유저가 실제로 아이템을 클릭한 경우 1, 클릭하지 않은 경우 0이다. Session의 길이는 대체로 짧기 때문에 overfitting을 방지하기 위하여 training step을 적게 하는 것이 좋다고 한다.
Dataset

저자들은 train 및 evaluation에 Yoochoose와 Diginetica 데이터셋을 사용하였다. 길이가 1인 session sequence과 5번 미만으로 나타나는 아이템은 데이터셋에서 제외했다고 한다. 그리고 session sequence와 label은 input sequence를 쪼개어서 만들었다고 한다. 예를 들면 데이터셋에서 어떠한 유저의 클릭 history가 $[v_{s,1}, v_{s,2}, ..., v_{s,n}]$이라고 하자. 그러면 (sequence, label) pair를 다음과 같이 n-1개 구할 수 있다.

Session sequence의 길이가 모델 성능에 영향을 줄까?
이를 검증하기 위해 저자들은 데이터셋을 "Short"과 "Long"으로 나누었다. 전자에는 길이가 5 이하인 session들이 속하고 후자에는 5보다 긴 session들이 속한다. Yoochoose의 약 70프로가 "Short"에 속하고 Diginetica의 약 76프로가 "Short"에 속한다. 5를 기준으로 나눈 이유는 두 데이터셋 모두 평균 session 길이가 약 5이기 때문이다. 비교 결과 SR-GNN은 두 집단에서 별 성능 차이를 보이지 않았다.
'추천시스템' 카테고리의 다른 글
| 랭킹 최적화 문제 (0) | 2022.07.18 |
|---|---|
| 정형 데이터를 다루기 위한 Neural Network (0) | 2022.01.18 |
| 추천시스템과 GNN(Graph Neural Network) (0) | 2022.01.18 |
| DQN 기반 추천시스템 (0) | 2022.01.18 |
| 강화학습을 이용한 Top-K 추천시스템 (0) | 2022.01.18 |



