"Recommendations with Negative Feedback via Pairwise Deep Reinforcement Learning" (https://arxiv.org/abs/1802.06501)을 통해 DQN으로 어떻게 추천시스템을 구현할 수 있는지 알아보자.
문제 제기
- 추천시스템과 상호작용하면서 유저의 선호도는 계속 변하는데 기존 알고리즘들은 추천을 정적인 프로세스로 모델링하고 fixed greedy strategy를 따른다.
- 기존 알고리즘들은 당장의 short-term reward만 고려하고 long-term reward를 최대화할 수 있는 아이템에 대한 추천을 간과한다.
- 유저의 클릭 이력(positive feedback)만큼이나 유저가 클릭하지 않고 지나친 아이템 정보(negative feedback)도 유저를 이해하는데 중요하다. 그러나 대체로 negative feedback이 positive feedback보다 훨씬 많기 때문에 positive, negative feedback을 함께 학습하는데 어려움이 있다.
MDP Formulation

State
\(s_+ = {i_1, ..., i_N}\)을 유저가 클릭한 최근 N개의 아이템 시퀀스, \(s_- = {j_1, ..., j_N}\)을 유저에게 노출되었으나 유저가 클릭하지 않은 최근 N개의 아이템 시퀀스라고 하자. 두 시퀀스의 아이템 순서는 클릭/노출 시간 순이다. 그러면 state는 \((s_+, s_-)\)로 정의한다.
Action
유저에게 추천해줄 아이템을 action으로 정의한다.
State Transition
State \(s = (s_+, s_-)\)인 유저에게 아이템 \(a\)를 추천해주었을 때, 유저가 \(a\)를 클릭했을 경우 \(s_+\)는 \({i_2, ..., i_N, a}\)로 업데이트된다. 반면 유저가 \(a\)를 클릭하지 않고 지나쳤을 경우 \(s_-\)가 \({j_2, ..., j_N, a}\)로 업데이트된다.
Reward
유저가 반응을 하지 않은 경우 0의 reward, 클릭 또는 주문을 한 경우 양의 reward를 부여한다.
DEERS Architecture
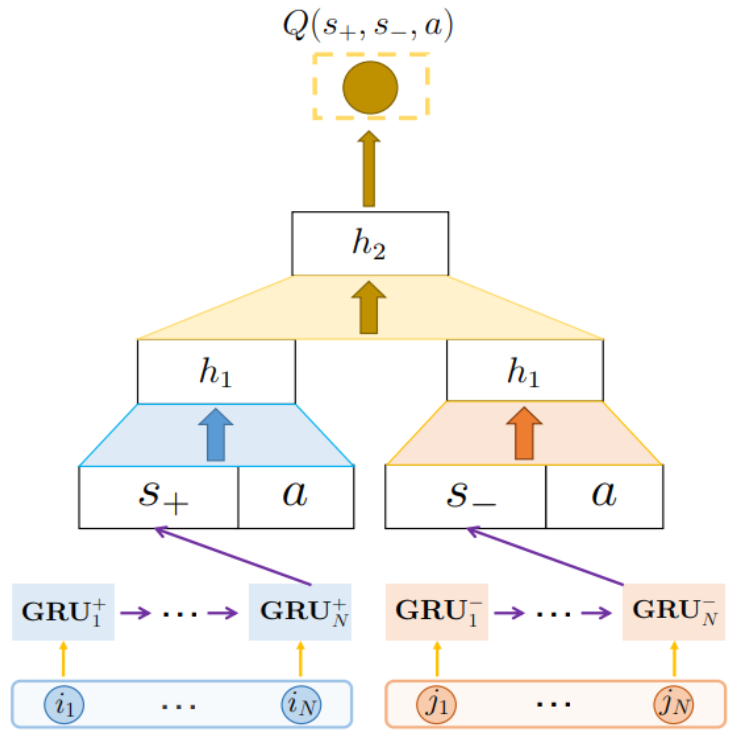
Positive feedback sequence와 negative feedback sequence는 각각 따로 GRU로 임베딩된 후 현재 추천하려는 아이템인 \(a\)와 concat되어 다시 한번 임베딩된다. 직관적으로 유저가 클릭한 적이 있는 아이템들과 비슷한 아이템은 추천하고 유저가 선택하지 않은 아이템과 비슷한 아이템은 추천하지 않기 위함이다. 네트워크 출력은 state가 \(s\)인 유저에게 \(a\)를 추천했을 때의 Q-value이다.
Pairwise Regularization Term
같은 카테고리에 있는 아이템 \(a_1\)과 \(a_2\)에 대하여 유저가 \(a_1\)을 클릭하고 \(a_2\)는 그냥 지나쳤다면 유저가 \(a_2\)보다 \(a_1\)을 더 선호하는 것이 명백하다. 저자들은 이러한 경우 \(a_2\)를 \(a_1\)의 competitor item이라고 불렀다. 임의의 item \(a\)의 competitor item을 \(a^C\)라고 하자. 그러면 \(Q(s,a)\)와 \(Q(s,a^C)\)의 차가 벌어지는 것이 추천에 도움이 될 것이다. 그래서 저자들은 loss에 \((Q(s,a)-Q(s,a^C))^2\)을 추가했다고 한다. 이 때 \(a\)에게 여러 competitor item이 존재할 수도 있다. 그럴 때는 \(a\)와 노출 시각이 가장 가까운 competitor item을 선택한다.
Algorithm Summary

Offline Test
Offline test에서 모델은 한 세션 내에 유저에게 노출되었던 아이템들의 Q-value를 각각 구한 후 그 값이 가장 큰 아이템을 추천한다. 전체 아이템이 아닌 해당 세션에서 노출되었던 아이템 내에서만 추천하는 이유는 노출되지 않았던 아이템에 대한 유저의 피드백을 알 수 없기 때문이다. 만약 여러 개의 아이템을 추천하고 싶으면 Q-value가 높은 순서대로 추천하면 된다.

'추천시스템' 카테고리의 다른 글
| 랭킹 최적화 문제 (0) | 2022.07.18 |
|---|---|
| 정형 데이터를 다루기 위한 Neural Network (0) | 2022.01.18 |
| Sequential Recommendation과 GNN (0) | 2022.01.18 |
| 추천시스템과 GNN(Graph Neural Network) (0) | 2022.01.18 |
| 강화학습을 이용한 Top-K 추천시스템 (0) | 2022.01.18 |



