"Graph Neural Networks in Recommender Systems: A Survey" (https://arxiv.org/pdf/2011.02260.pdf) 내용 정리 - 그래프와 GNN은 추천시스템에 어떻게 적용되는가?
GNN이란 무엇인가?
GNN은 말 그대로 그래프 구조의 데이터를 다루기 위한 neural network이다. GNN의 큰 틀은 다음과 같다. (사진 출처 : https://arxiv.org/pdf/1706.02216.pdf)

바깥 루프가 한 번 돌 때마다 각 노드는 (1) neighbor aggregation과 (2) information update라는 두 과정을 거친다. Neighbor aggregation은 임의의 aggregator function을 통해 기준 노드의 이웃 노드들의 hidden state들을 하나의 벡터로 합치는 것을 의미한다. 가장 많이 사용하는 aggregator function으로 mean pooling, max pooling, LSTM 등이 있다.
Information update는 neighbor aggregation으로 생성된 벡터와 기준 노드의 hidden state를 함께 처리하여 새로운 벡터를 얻어서 기준 노드의 hidden state를 이 벡터로 업데이트하는 것을 의미한다.
한 번의 (바깥) 루프가 돌 때마다 각 노드의 정보가 그 이웃 노드들에게 전달된다. 루프가 K번 돌면 특정 노드의 정보가 K개의 edge만큼 떨어진 노드에게 전달될 것이다. 그래서 neighbor aggregation과 information update을 합쳐서 propagation(전달)이라고 한다. 위의 예시에서는 K번의 propagation이 발생하였다.
서로 다른 GNN 알고리즘들은 aggregator function과 information update 방식에서 차이를 보인다. 대표적인 GNN 알고리즘으로 GCN(Graph Convolutional Network), GAT(Graph Attention Network), GGNN(Gated Graph Sequence Neural Networks) 등이 있다.
GNN이 추천시스템에 어떻게 적용될까?
GNN 기반 추천 방식은 대체로 general recommendation과 sequential recommendation 중 하나로 분류할 수 있다.
General Recommendation

General recommendation 방식에서는 주로 위와 같은 user-item bipartite graph를 이용한다. User-item bipartite graph란 각 유저와 추천 대상 아이템(ex. 광고, 영화, 상품, etc.)을 노드로 하고, 어떤 유저가 특정 아이템을 선택(클릭, 시청, 구매, etc.)한 적이 있을 경우 해당 유저와 아이템을 연결한 그래프이다. 인공 신경망은 유저의 과거 아이템 선택 이력를 통해 유저의 취향을 계산하고, 유저가 이전에 선택하지 않은 아이템이 주어졌을 때 유저가 해당 아이템을 선택할 확률을 출력하도록 학습된다. 유저의 취향은 시간에 따라 변하지 않는다고 가정한다.
Sequential Recommentation

실제로는 유저의 취향은 고정되어 있지 않다. Sequential recommendation은 유저의 취향이 시간에 따라 변한다고 가정한다. 위의 그림에서처럼 유저가 과거에 선택한 아이템들이 시간 순서대로 주어지면 그 sequence는 그래프로 변환된다. $i_m$ 다음에 $i_n$을 선택했다면 $i_m$에서 $i_n$으로 나가는 화살표를 그리는 방식이다.

위 그림이 sequential recommendation의 보편적인 framework라고 보면 된다. 그래프가 GNN으로 처리되면 각 노드의 정보가 하나의 벡터로 임베딩된다. 이 벡터들은 RNN으로 처리된다. RNN의 final hidden state는 유저가 다음에 클릭할 아이템을 예측하는데 사용된다.
Social Relationship Graph와 Knowledge Graph

User-item bipartite graph나 item sequence graph만으로는 유저의 취향에 대한 정보를 충분히 얻기가 어려운 경우가 많다. 그래서 보통 여러 유저 간의 관계를 나타내는 social relationship graph나 아이템의 여러 속성들을 통해 여러 아이템 간의 관계를 묘사하는 knowledge graph를 GNN으로 함께 처리한다.
User-Item Bipartite Graph + Social Relationship Graph
Social relationship graph는 우리의 취향이 가까운 사람으로부터 영향을 받는다는 사실과 한 사람의 영향력이 그의 지인의 지인, 지인의 지인의 ... 지인으로 확산된다는 사실에 근거한다. 그러나 같은 지인이라도 친밀도와 유사도 등에 따라 받는 영향력이 다를 것이다. 그래서 social relationship graph에서 기준 노드에 대한 이웃 노드들의 영향을 계산할 때 attention이 사용되기 시작했고 이는 실제로 성능 향상으로 이어졌다. 그러나 social relationship graph를 완전히 신뢰하기는 힘들다는 주장도 있다. 그 이유는 친밀도가 아이템 선호도에 영향을 주지 않는 경우도 많으며 social relationship graph는 대체로 불완전하기 때문이다.
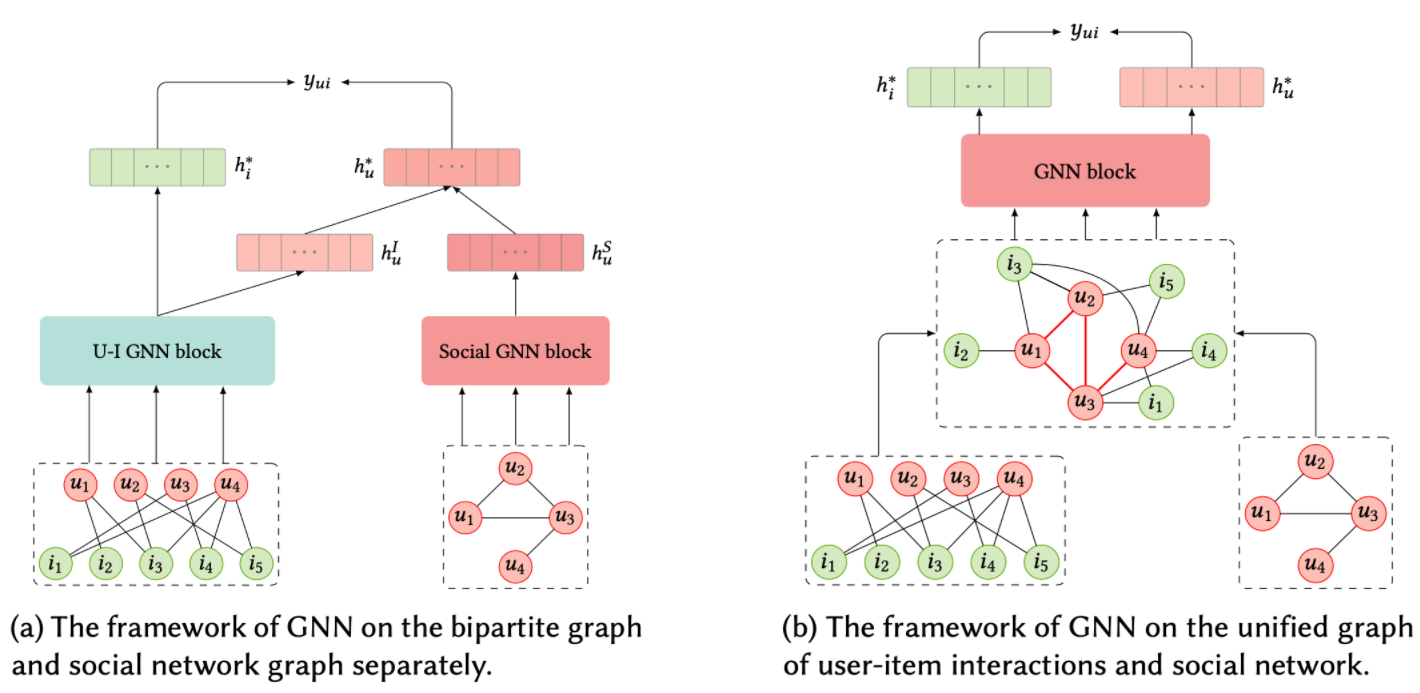
User-item bipartite graph와 social relationship graph을 인공 신경망으로 처리하는 방식은 위의 그림에서처럼 크게 두 가지로 나뉜다. (a) User-item bipartite graph와 social relationship graph를 각각 다른 GNN으로 처리한 후 통합하는 방법과 (b) user-item bipartite graph와 social relationship graph를 하나의 그래프로 통합한 후 GNN을 적용하는 방법이 있다.
최종 output은 $y_{ui}$, 즉 유저 $u_i$가 아이템 $i$를 선택할 확률이다.
User-Item Bipartite Graph + Knowledge Graph
Knowledge graph는 아이템의 여러 속성들을 이용하여 여러 아이템 간의 관계를 나타낸다. 구체적으로 그래프는 (아이템(node), 관계(edge), 속성(node)) tuple들로 구성된다고 보면 된다. 한 아이템은 직접적으로 자신의 속성들과 연결되었고 각 속성과의 관계가 edge에 임베딩되는 것이다. 예를 들면 컨저링이라는 아이템과 호러라는 속성이 "영화-장르"라는 관계로 연결된다. 인셉션이라는 아이템과 레오나르도 디카프리오라는 속성이 "영화-주연배우"라는 관계로 연결된다. 관계를 속성의 카테고리라고 이해하면 좋을 것 같다. 같은 속성을 공유한 다른 아이템(호러 장르의 다른 영화, 레오나르도 디카프리오의 다른 주연 영화)과는 두 다리 건너 연결된다.
Knowledge graph에 GNN이 어떻게 적용되는지 보기 위해 https://arxiv.org/pdf/1904.12575.pdf 에서 제안한 KGCN(Knowledge Graph Convolutional Network)을 살펴보자. KGCN은 어떠한 유저 $u$가 아이템 $v$를 클릭할 확률을 구하고자 한다. $N(v)$를 $v$의 이웃 노드($v$의 속성을 대표하는 노드)의 집합, $r_{v, e}$를 노드 $v$와 $e$ 사이의 관계, $g$를 내적 연산이라고 하자. 우선 $u$와 $r$ 사이의 score를 다음과 같이 정의한다. (각 노드는 이미 vector representation으로 embedding 되었다고 가정한다.)
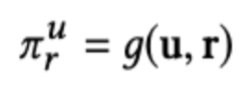
이 score는 $u$가 $r$이라는 관계(속성 카테고리)를 얼마나 중시하는지를 나타내는 수치인 것이다. 예를 들면 어떠한 유저에게는 영화의 주연 배우가 누구인지가 중요할 수 있고, 다른 유저에게는 영화의 장르가 무엇인지가 더 중요할 수 있다. 이제 $v$의 이웃 노드들의 (유저 $u$의 입장에서의) 가중치합을 다음과 같이 구할 수 있다.

한 가지 고려해야할 것은 노드마다 degree(연결된 edge의 개수)가 매우 다를 것이라는 점이다. 그래서 각 batch마다 계산량을 일정하게 유지하기 위해서 노드마다 일정한 개수의 이웃 노드를 샘플링하는 방식을 채택했다고 한다.
이제 남은 일은 $v$와 $v^u_{N(v)}$를 하나의 벡터로 합치는 것이다. 저자들은 (1)summation, (2)concatenation, (3)$v$ 제외, 이 세 가지 방법 중 하나씩 선택해서 적용한 후 (MLP layer + activation)을 적용해보고 그 결과를 비교하였다.
이로써 하나의 propagation이 완료되었다. 이 propagation을 여러 번 수행하여 knowledge graph의 여러 노드들 간의 high-order interaction을 모델링할 수 있다.
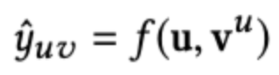
마지막 propagation 후의 결과물 $v^u$와 user representation $u$를 $f$라는 함수(neural network)에 통과시킨다. 이로써 최종적으로 $u$가 $v$를 클릭할 확률의 예측값 $y_{uv}$이 출력된다. Loss function은 cross entropy와 negative sampling loss의 합으로 구성하였다고 한다.
'추천시스템' 카테고리의 다른 글
| 랭킹 최적화 문제 (0) | 2022.07.18 |
|---|---|
| 정형 데이터를 다루기 위한 Neural Network (0) | 2022.01.18 |
| Sequential Recommendation과 GNN (0) | 2022.01.18 |
| DQN 기반 추천시스템 (0) | 2022.01.18 |
| 강화학습을 이용한 Top-K 추천시스템 (0) | 2022.01.18 |



