Knowledge graph는 추천시스템에서 추천 대상 아이템들에 대한 정보를 추출하는데 유용한 툴이다. 최근에는 유저-아이템 간의 상호작용 데이터가 부족한 상황에서 collaborative filtering 기반 추천시스템을 보완하는데 많이 활용되고 있다. Knowledge graph는 추천을 설명 가능하게(explainable) 해준다는 점에서도 주목을 받고 있다. 그래프 상에서 유저가 이전에 좋아한 아이템과 여러 특성을 공유한다는 근거를 들어 새로운 아이템을 유저에게 추천해줄 수 있다.
본 포스트에서는 knowledge graph란 구체적으로 어떤 형태의 그래프인지, 그리고 딥러닝 기반 추천시스템에서 knowledge graph를 어떻게 활용할 수 있는지에 대하여 다룰 것이다. A Survey on Knowledge Graph-Based Recommender Systems 와 A Survey on Knowledge Graph Embedding: Approaches, Applications and Benchmarks 를 참고하였다.
Knowledge Graph란 무엇인가
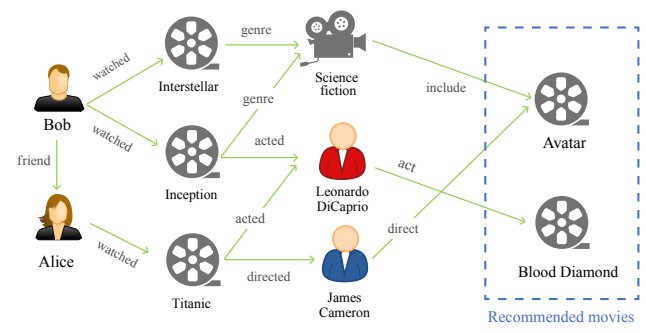
Knowledge graph는 기본적으로 (head entity, relation, tail entity) triple들로 구성되었다. Entity는 아이템 혹은 아이템의 특성, 카테고리 등을 종합한 개념이고 각 entity는 그래프에서 하나의 노드가 된다. Relation은 두 entity 간의 관계로 그 둘을 연결하는 edge로 매핑된다.
예시를 보면 더 쉽게 이해될 것이다. 그림에서 추천 대상 영화들과 각 영화를 특징지을 수 있는 장르, 배우, 감독 등이 그래프의 노드다. 그리고 edge에는 양 끝 노드 간의 관계가 적혀있다. (Titanic, acted, Leonardo Dicaprio) triple은 타이타닉과 디카프리오가 영화-배우 관계임을, (Interstellar, genre, Science Fiction)은 인터스텔라와 SF가 영화-장르 관계임을 의미한다. 인터스텔라와 인셉션은 같은 노드와 장르라는 관계로 연결되었기 때문에 어느 정도 유사할 것임을 예측할 수 있다.
설계에 따라 추천 대상 아이템 뿐만 아니라 유저도 knowledge graph의 노드로 추가할 수 있다. 시청, 클릭, 조회, 구매 등 유저가 아이템을 선택할 때 행하는 action을 relation으로 정의하여 이전에 상호작용이 있었을 경우 해당 유저 노드와 아이템 노드를 연결할 수 있다. 이 경우 각 아이템을 선호하는 유저들의 정보도 자연스럽게 활용할 수 있게 된다.
Knowledge Graph Embedding
우리의 knowledge graph로부터 어떤 수치적인 결과를 얻고자 한다면 먼저 그래프의 entity와 relation들을 임베딩할 필요가 있다. 그래프의 규모가 매우 큰 경우 계산량과 data sparsity로 인해 유의미한 결과를 못 얻을 수가 있다. 그래서 continuous하고 차원이 낮은 vector로 임베딩하는 것이 중요하다. 고전적인 임베딩 방법도 많지만 본 포스트에서는 딥러닝으로 entity와 relation들의 representation을 학습하는 방법에 대하여 다루겠다.
학습 루틴
앞으로 head entity를 $h$, tail entity를 $t$, relation을 $r$이라고 표기하고 이들로 구성된 triple을 $(h, r, t)$로 나타내겠다. 어떠한 학습 가능한 scoring function $f_r(h, t)$가 존재하여 각 triple을 스칼라 값으로 매핑한다고 가정하자.

먼저 knowledge graph의 triple들을 모아 집합 $S$를 구성하고 각 entity와 relation의 임베딩을 랜덤한 $k$-dimensional 벡터로 초기화한다. 그 다음 학습 이터레이션을 시작한다. 매 이터레이션마다 $S$로부터 triple $b$개를 샘플링하여 batch $S_{batch}$를 구성한다. 그리고 $S_{batch}$의 각 triple로부터 corrupt triple을 하나씩 생성한다. Corrupt triple이란 "틀린" triple 혹은 그래프에 존재하지 않는 triple로 원래 triple에서 head 또는 tail entity를 다른 entity로 대체해서 만들어진다. 기존의 triple을 $(h, r, t)$, 그의 corrupt triple을 $(h', r, t')$으로 표기한다면 $h$와 $t$는 $r$ 관계에 있는 반면 $h'$과 $t'$은 $r$ 관계에 있지 않은 것이다. $\{(h, r, t), (h', r, t')\}$ 쌍들로 이루어진 batch $T_{batch}$에 대하여 loss function에 대한 gradient descent를 수행한 후 다음 이터레이션으로 넘어간다.
Loss function으로는 다음 두 함수를 많이 사용한다.
Margin-Based Loss Function
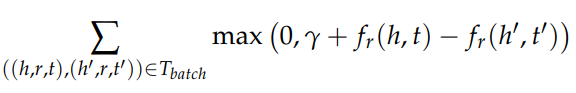
$\gamma > 0$는 margin hyperparameter다.
Logistic Loss Function
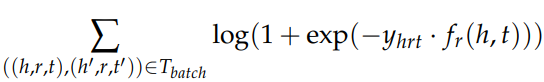
$y_{hrt}$는 label로 correct triple에 대해서는 1, corrupt triple에 대해서는 -1의 값을 갖는다.
모델 아키텍처
Scoring function $f_r(h, t)$를 정의하고 딥러닝 모델을 설계하는 일은 열린 문제다. 몇 가지 예시를 소개하겠다. $h$, $r$, $t$의 임베딩을 각각 h, r, t라고 하자. 또한 학습 가능한 weight matrix를 M, weight vector를 w, bias vector를 b로 표기하겠다.
SME
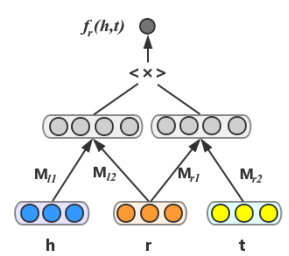
SME는 먼저 head entity와 relation의 조합, 그리고 tail entity와 relation의 조합을 각각 임베딩한다.
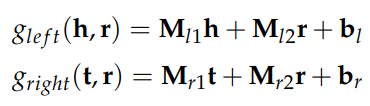
또는
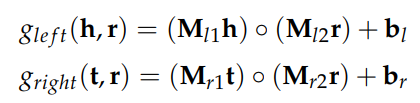
그 둘을 내적하여 score를 계산해낸다.
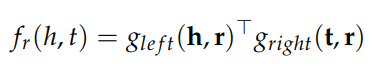
NAM
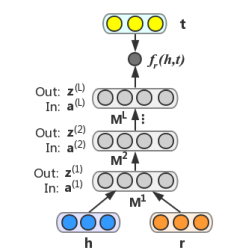

NAM은 h와 r을 concatenate한 다음 fully connected layer들로 처리한다. 그 결과를 t와 내적하여 최종적으로 sigmoid 함수를 적용해서 score를 구한다.
RMNN
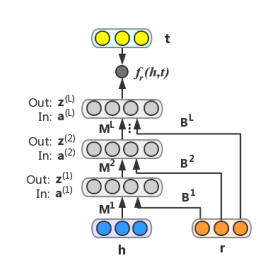
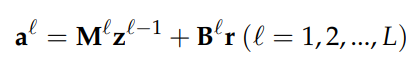
RMNN은 NAM이 조금 더 복잡하게 변형된 형태다. Bias vector $b_l$ 대신 bias matrix $B_l$과 r의 곱을 더한다.
ConvKB
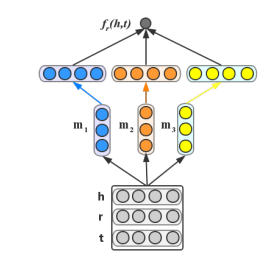
ConvKB는 CNN을 이용하여 임베딩한다. 우선 h, r, t를 stack하여 행렬 $A =$ [h; r; t]를 만든다. h, r, t의 dimension이 $d$라면 $A$는 $3$x$d$ 크기의 행렬이 되는 것이다. $3$x$1$ 크기의 필터 $m$을 적용하면 $d$-dimensional vector의 feature map이 생성된다. $N$개의 필터를 적용하면 이러한 feature map이 $N$개 나온다. 이 feature map들을 concatenate하면 $Nd$ 크기의 벡터를 얻게 되고 이를 동일한 크기의 weight vector w와 내적하여 최종 score가 도출한다. 그림에서는 $N=3$이다.
GNN
앞서 설명한 knowledge graph embedding만 적용할 경우 각 node의 embedding이 인접한 neighbor node들의 정보만 담아내기 때문에 제한적이다. 임베딩된 그래프에 GNN으로 추가적인 학습을 한다면 각 node에 그로부터 $K$개의 edge만큼 떨어진 다른 node의 정보를 담아낼 수 있다. Knowledge graph에 GNN을 적용한 사례는 추천시스템과 GNN(Graph Neural Network) 혹은 KGCN 논문에서 찾아볼 수 있다.
Knowledge Graph 밖의 정보 활용
많은 경우 추천시스템은 knowledge graph 외에도 user-item interaction matrix, 아이템과 관련된 텍스트나 이미지 등으로부터 추천에 필요한 정보를 추출한다. 여러 출처들로부터 얻은 임베딩을 종합하여 최종 임베딩을 도출하게 된다. 가장 간단한 예로는 user-item interaction matrix, 아이템에 대한 문자 설명, 아이템의 이미지, knowledge graph로부터 각각 얻은 아이템의 임베딩을 전부 더하는 것이다.
추천 점수 출력
마지막으로 아이템 임베딩을 이용하여 유저가 특정 아이템을 선택할 확률을 출력하면 추천시스템이 완성된다. 먼저 아이템처럼 유저들 또한 아이템 임베딩과 같은 크기의 벡터로 임베딩되었다고 가정하자. 유저 $i$의 임베딩을 $u_i$, 아이템 $j$의 임베딩을 $v_j$라고 할 때 이 둘을 0~1 사이의 값으로 매핑하는 함수 $f$를 정의하여 예측 확률 $y_{i,j}$를 출력하면 된다.
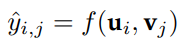
간단한 예로 $f$를 내적 후 sigmoid activation으로 정의할 수 있다. 더 복잡한 예로는 $f$를 딥러닝 모델 같은 학습 가능한 함수로 정의할 수 있다. 과거 유저들의 아이템 선택 정보로 학습 데이터를 구성하여 유저가 선택한 아이템에 대해서는 1, 선택하지 않은 아이템에 대해서는 0으로 labeling한 후 regression loss를 정의하여 $f$의 파라미터들을 학습하는 방법도 많이 채택되고 있다.
Multi-Task Learning
지금까지의 내용을 종합하면 마치 knowledge graph를 이용한 아이템 임베딩을 따로 먼저 학습한 후 추천 확률을 출력하는 함수를 학습해야되는 것처럼 보인다. 하지만 꼭 그럴 필요는 없다. 아이템 임베딩 함수와 추천 함수를 동시에 학습하는 방법도 있고 문제에 따라 이것이 더 효과적일 수도 있다. 유저와 아이템 간의 과거 interaction 정보로부터 추천 여부를 학습하기 위한 loss function을 $L_{rec}$, knowledge graph의 triple set으로부터 아이템 임베딩을 학습하기 위한 loss function을 $L_{KG}$라고 하자. 그러면 최종 loss function을 다음과 같이 정의하여 모든 파라미터들을 하나의 학습 루틴으로 학습시킬 수 있다.
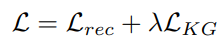
여기서 $\lambda$는 hyperparameter로 두 task 사이의 가중치를 지정하는 용도다.
'추천시스템' 카테고리의 다른 글
| 추천시스템의 분류 (0) | 2022.10.21 |
|---|---|
| Continual Learning in Recommender Systems (0) | 2022.08.28 |
| 랭킹 최적화 문제 (0) | 2022.07.18 |
| 정형 데이터를 다루기 위한 Neural Network (0) | 2022.01.18 |
| Sequential Recommendation과 GNN (0) | 2022.01.18 |


