A/B Testing with Seldon Core에서 라우터는 두 모델에 보낼 트래픽을 나누는 역할을 하였다. 보통 A/B Testing의 궁극적 목표는 여러 모델 중에서 가장 좋은 모델을 찾는 것이다. 다행히도 라우터에 각 모델 inference에 대한 피드백을 받아서 모델 성능을 기록하고 라우팅에 반영하는 기능을 추가할 수 있다.
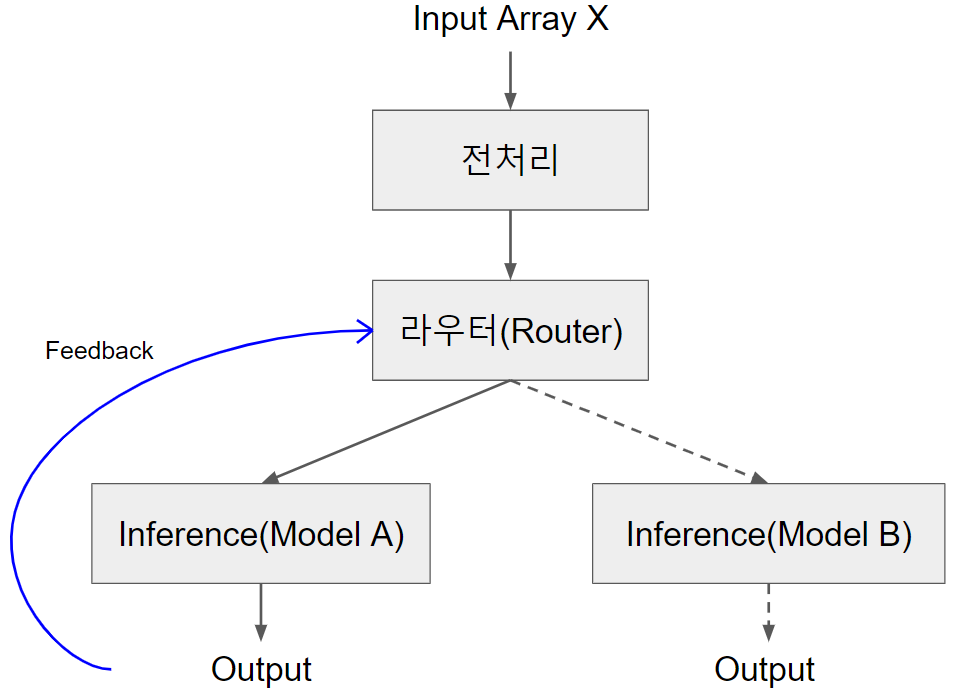
셀던 코어에서는 라우터에서 선택된 모델의 inference에 대한 피드백을 reward라는 숫자로 받을 수 있다. 추천시스템을 예로 들자면, 모델에게 추천받은 컨텐츠를 유저가 클릭하거나 구매했을 경우 1, 그렇지 않았을 경우 0의 reward를 줄 수 있고, 또는 유저가 부여한 평점을 reward로 줄 수도 있다. 우리의 문제에서는 reward가 무조건 1 또는 0의 값을 갖는다고 가정한다. 라우터는 이러한 피드백들을 모아서 점점 어느 모델이 더 좋은가에 대한 판단을 하게 되고 더 나은 모델에게 트래픽을 더 많이 보내게 된다.
이러한 문제를 multi-armed bandit이라고 한다. 처음에는 여러 선택지를 랜덤하게 탐색하여 정보를 얻고 정보가 충분히 모이면 가장 큰 이득을 가져올 것으로 추정되는 선택지를 greedy하게 선택하는 것이다. Multi-armed bandit 문제를 해결하는 알고리즘에는 여러 가지가 있는데 우리는 그 중에서 epsilon greedy와 thompson sampling을 라우터에 구현해보자.
Epsilon Greedy
우리는 각 모델의 reward가 베르누이 분포를 따른다고 가정할 것이다. 베르누이 분포는 $p$의 확률로 1이 나오고 $1-p$의 확률로 0이 나오는 분포다. 라우터는 피드백을 모아서 각 모델의 $p$값을 추정해야한다. 추정된 $p$값이 가장 높은 모델이 현재까지 가진 정보로는 가장 좋은 모델이라고 판단될 것이다.
Epsilon Greedy는 $1 - \epsilon$의 확률로 $p$값이 가장 높은 모델을 선택하고 $\epsilon$의 확률로 무작위로 선택하여 더 넓은 탐색의 기회를 열어놓는다. Router.py에 Epsilon Greedy를 구현해보자.
import random
import numpy as np
from seldon_core.user_model import SeldonComponent
class Router(SeldonComponent):
def __init__(self, n_branches=2, epsilon=0.1):
super(Router, self).__init__()
self.n_branches = int(n_branches)
self.epsilon = float(epsilon)
self.best_branch = random.choice(range(self.n_branches))
self.branch_success = [0] * self.n_branches
self.branch_tries = [0] * self.n_branches
self.branch_values = [0] * self.n_branches
def route(self, features, feature_names=None):
x = random.random()
selected_branch = self.best_branch if x > self.epsilon else random.choice(range(self.n_branches))
return int(selected_branch)
def send_feedback(self, features, feature_names, reward, truth, routing=None):
self.branch_success[routing] += reward
self.branch_tries[routing] += 1
self.branch_values[routing] = self.branch_success[routing] / self.branch_tries[routing]
self.best_branch = np.random.choice(np.where(np.array(self.branch_values) == max(self.branch_values))[0])
해석을 하자면 각 모델마다 $p$값을 (긍정적 피드백 수) / (총 피드백 수)로 추정하고 Epsilon Greedy를 수행한다.
send_feedback이 피드백을 받는 함수이다. 파라미터 중 reward에 피드백 reward 값이, routing에는 해당 피드백이 어떤 모델에 대한 피드백인지에 대한 정보가 들어온다. $n$번째 모델에 대한 피드백이면 $n-1$이라는 integer 값이 들어오는 것이다.
Thompson Sampling
Thompson 샘플링은 매 요청마다 각 모델의 $p$ 값을 베타 분포에서 샘플링하고 샘플링된 $p$값이 가장 큰 모델을 선택하는 방식으로 탐색을 한다. 이에 대한 수학적 근거는 바로 베르누이 분포의 conjugate prior가 베타 분포라는 것이다.
$p$ ~ $Beta(a,b)$
베타 분포는 두 파라미터 $a$와 $b$를 갖고 분포의 평균은 $\frac{a}{a+b}$가 된다.
처음에 각 모델의 $a$와 $b$를 1로 초기화한다. 이후 어떤 모델이 선택되어 피드백을 받으면 해당 모델의 $a$에 reward를, $b$에 (1-reward)를 더한다. $a$는 모델의 현재까지의 긍정적 피드백 수, $b$는 부정적 피드백 수가 되는 것이다. 각 모델의 베타 분포의 평균은 (긍정적 피드백 수) / (총 피드백 수)가 된다.
라우터는 초반에는 넓게 탐색을 하게 된다. 그러다 피드백이 많이 쌓인 모델들의 베타 분포의 분산이 점점 작아지면서 어느 정도 수렴하게 된다.
그럼 Router.py에 Thompson 샘플링을 구현해보자.
import numpy as np
from seldon_core.user_model import SeldonComponent
class Router(SeldonComponent):
def __init__(self, n_branches=2):
super(Router, self).__init__()
self.n_branches = int(n_branches)
self.models_beta_params = [[1, 1]] * self.n_branches
def route(self, features, feature_names=None):
branch_values = [np.random.beta(a, b) for a, b in self.models_beta_params]
selected_branch = np.argmax(branch_values)
return int(selected_branch)
def send_feedback(self, features, feature_names, reward, truth, routing=None):
self.models_beta_params[routing][0] += reward
self.models_beta_params[routing][1] += 1 - reward
피드백 요청 보내기
import requests, json
session = requests.Session()
#예측 요청
prediction_url = 'http://{ingress URL}/seldon/{kubeflow namespace}/{seldon deployment name}/api/v1.0/predictions'
headers = {'Content-Type': 'application/json'}
prediction_data = {'data': {'ndarray': [['dog', 0, 4, 0.2, 0.79, ...], ...]}}
res = session.post(prediction_url, data=json.dumps(prediction_data), headers=headers)
#피드백 요청
feedback_url = 'http://{ingress URL}/seldon/{kubeflow namespace}/{seldon deployment name}/api/v1.0/feedback'
feedback = 1
feedback_data = {'response': res.json(), 'reward': feedback}
session.post(feedback_url, data=json.dumps(feedback_data), headers=headers)
'MLOps' 카테고리의 다른 글
| AWS Serverless 1편 (0) | 2023.01.02 |
|---|---|
| Amazon SageMaker (0) | 2022.04.25 |
| Ensemble with Seldon Core (0) | 2022.02.19 |
| 셀던 코어와 텐서플로우 서빙 (0) | 2022.02.07 |
| A/B Testing with Seldon Core (0) | 2022.02.07 |

